✍️단순 LLM 호출과 에이전트는 무엇이 다른가 / RAG, ReAct, 그리고 판단을 데이터로 검증하기
·
12 views
·20 min read
LLMAITool Calling
이 글이 따라가는 길
개념 → 경계 → 원리(ReAct·계보) → 응용(사례) → 심화(실패·평가·안전)
오늘날 LLM이 들어간 거의 모든 기능이 "에이전트"라 불린다. 그러나 이렇게 불리는 것의 상당수는, 잘 구조화된 단일 API 호출 한 번으로 동일한 결과를 낼 수 있는 것들이다. 어떤 기능에 LLM이 관여한다는 이유로 "에이전트"라는 범주가 대화에 끼어들고, 에이전트 프레임워크가 선택되고, 다단계 루프가 구축되고, 복잡도가 불어난 끝에, 6주 뒤 잘 구조화된 호출 한 번이면 똑같이 나왔을 출력을 내는 정교한 시스템이 만들어진다.
이 인플레이션의 비용은 단지 미관의 문제가 아니다. 불필요한 에이전트화는 지연(latency), 토큰 비용, 디버깅 부담, 그리고 뒤에서 다룰 고유한 실패 모드를 함께 들여온다. 따라서 "무엇이 에이전트인가"를 정확히 긋는 일은 이론적 정밀함이 아니라 실무적 절약의 문제다.
이 글은 개념 → 경계 → 원리 → 응용 → 심화의 순서로 그 경계를 따라간다.
자주 혼용되는 세 가지를 먼저 분리한다.
단일 LLM 호출 (Single Call). 입력을 주면 출력이 나온다. 한 번으로 끝난다.
입력 → LLM → 출력
순수한 LLM은 프롬프트를 받아 텍스트를 생성할 뿐이며, 현재 컨텍스트를 넘어서는 기억도, 외부 도구를 호출할 수단도, 자율적으로 목표를 추적할 능력도 갖지 않는다. "이 문장을 요약하라", "이 리뷰의 감성을 분류하라" 같은 작업이 여기 속한다. 실무에서 다루는 대다수의 "AI 기능"은 사실 이 범주로 충분하다.
RAG (검색 증강 생성, Retrieval-Augmented Generation). LLM이 알지 못하는 정보를 미리 검색해 프롬프트에 주입한 뒤 답하게 하는 방식이다.
관련 문서 검색 → 프롬프트에 주입 → LLM → 출력
여기서 결정적인 점은, 검색이 LLM 호출에 선행하여 단 한 번 일어난다는 것이다. LLM은 주어진 자료를 근거로 답할 뿐, "더 찾아볼지"를 스스로 결정하지 않는다. 검색의 시점과 범위가 코드에 의해 고정된다. 따라서 RAG는 단일 호출의 확장이며, 아직 에이전트가 아니다.
에이전트 (Agent). 여기서부터 범주가 바뀐다. 가장 간결한 정의로, 에이전트는 도구를 루프 안에서 자율적으로 사용하는 LLM이다. 일반적인 LLM과 달리 에이전트는 중간 결과를 평가하고 자신의 오류로부터 동적으로 회복하며, 이 루프 안에서 작동해야 한다.
목표 → [ 생각 → 행동(도구) → 관찰 → 다시 생각 → ... ] → 결과
핵심은 두 가지, 루프와 자율성이다. LLM이 "지금 무엇이 필요한가"를 스스로 판단해 도구를 사용하고, 그 결과를 관찰한 뒤 다음 행동을 결정한다. 한 번 묻고 한 번 답하는 것이 아니라, 상황에 따라 스스로 경로를 구성한다.
세 범주의 비교
| 구분 | 단일 호출 | RAG | 에이전트 |
|---|---|---|---|
| 흐름 | 입력→출력 | 검색→주입→출력 | 생각→행동→관찰 루프 |
| 도구 사용 | 없음 | 호출 전 1회(고정) | 루프 중 LLM이 결정 |
| 반복 | 없음 | 없음 | 결과 보고 반복 |
| 오류 회복 | 없음 | 없음 | 관찰 보고 전략 수정 |
| 주도권 | 코드 | 코드 | LLM |
| 적합한 작업 | 분류·요약·생성 | 지식 기반 응답 | 다단계 판단·검증 |
| 주된 비용 | 1회 호출 | 1회 호출 + 검색 | 다회 호출 + 루프 오버헤드 |

[그림 1. 단일 호출 · RAG · 에이전트의 흐름 비교 — 앞의 둘은 직선, 에이전트만 루프를 돈다]
참고
개념적 구분은 명료하지만, 실무에서 진짜 어려운 것은 "이 기능이 에이전트인가 아닌가"의 판정이다. 가장 쓸모 있는 판별 기준은 다음 한 문장으로 요약된다.
도구 호출이 추론 과정의 일부인가, 아니면 LLM 호출 전후에 처리될 수 있는 단순 데이터 조회 단계인가.
사용자의 계정 이력을 가져와 LLM에 넘겨 분류하게 하는 것은 에이전트가 아니라 전처리다. 반면 첫 결과가 의문을 남겨 LLM이 계정 이력을 추가로 더 조회하기로 스스로 결정하고, 그 결과 전체를 가로질러 추론하는 것은 에이전트적 사용이다.
즉 같은 "DB 조회"라도 두 경우가 갈린다.
따라서 결정 규칙은 단순해진다. 다단계 추론·도구 사용·결정 루프·계획 수립이 필요한 작업에만 에이전트를 쓴다. 그 외에는 단일 호출이 옳다.

[그림 2. "에이전트가 필요한가" 결정 트리 — 세 질문을 통과해야 에이전트에 닿는다]
참고
에이전트를 "생각·행동·관찰의 루프"라 했는데, 이는 추상적 비유가 아니라 구체적 패턴이며, 그 원형이 ReAct다.
ReAct의 정의. ReAct(Reasoning + Acting)는 원샷 LLM을 세계에 행동을 가하는 시스템으로 바꾸는 프롬프트 패턴이다. 원전(Yao et al., 2022)은 모델이 Thought(자유 텍스트 추론), Action(도구 호출), Observation(도구 결과)을 번갈아 생성하며 최종 답에 이를 때까지 루프를 도는 단순한 템플릿을 제시했다. 코딩 어시스턴트, 리서치 에이전트, 브라우저 사용 에이전트에 이르기까지 거의 모든 현대 에이전트가 ReAct의 후손이다.
루프 한 주기는 세 단계로 구성된다.

[그림 3. ReAct 루프 — Thought → Action → Observation을 돌다 충분하면 답을 낸다]
핵심﹗ 열린 루프 대 닫힌 루프. 이 부분이 ReAct의 본질이자, 에이전트가 단일 호출보다 강한 이유의 핵심이다.
순수한 사고 연쇄(Chain-of-Thought)는 닫힌 루프다. 모델이 자기 훈련 기억에 기대어 추론하므로, 중간 사실을 환각할 수 있다. 추론이 외부 세계와 단절되어 있기 때문에, 틀린 전제 위에 그럴듯한 결론이 쌓인다.
ReAct는 추론 단계들 사이에 실제 관찰을 끼워넣어 루프를 연다. 모든 사실이, 다음 생각이 그 위에 쌓이기 전에 외부 확인으로 검증된다. 즉 매 단계마다 현실의 데이터가 한 번씩 주입되어 추론이 현실에 묶인다. 이것이 실세계 정보가 필요한 모든 작업(웹 검색, 코드 실행, DB 쿼리)에서 오류 표면(error surface)을 줄인다.
부수적 이득이 하나 더 있다. 도구 호출이 "결과 없음"을 반환하면, 모델은 다음 Thought에서 그럴듯한 답을 지어내는 대신 전략을 수정할 수 있다. 닫힌 루프에는 없는 우아한 실패 모드(graceful failure) 다.
정리하면 ReAct(에이전트)가 단일 호출보다 강한 이유는 두 가지로 압축된다.
참고
ReAct는 고립된 발명이 아니라 하나의 계보 위에 있다. 단일 도구 호출에서 다중 도구 오케스트레이션으로 이어지는 이 진화를 따라가면, 에이전트 설계의 지형이 보인다.
Chain-of-Thought (CoT) / 추론만. 가장 앞에 사고 연쇄가 있다. 모델에게 "답하기 전에 단계적으로 추론하라"고 지시한다. 수학 문제나 논리 추론에 유용하다. 그러나 CoT는 도구를 부르거나 도중에 새 정보를 받지 않는다. 모델은 이미 아는 것 위에서만 추론한다. 즉 닫힌 루프다.
ReAct / 추론 + 행동. CoT에 행동을 더한 것이 ReAct다. 추론 사이에 실제 도구 호출과 관찰을 끼워, 모델이 추론 도중 새 정보를 가져오게 한다. CoT가 머릿속에서만 추론했다면, ReAct는 추론 중에 세계와 상호작용한다. 이 한 걸음이 닫힌 루프를 열린 루프로 바꾼다.
Reflexion / 자기 반성. Reflexion(Shinn et al., 2023)은 ReAct에 언어적 강화(verbal reinforcement) 를 더한다. 에이전트가 시도에 실패하면, 무엇이 잘못됐는지를 자연어 자기 반성으로 적어 다음 시도의 컨텍스트에 넣는다. 모델 가중치를 갱신하는 대신 "말로 된 교훈"을 메모리에 쌓아 다음 궤적을 개선한다. 출력 품질을 단일 응답 수준에서 끌어올리는 자기 교정 계열(Self-Refine, Self-Consistency 등)의 대표 격이다.
Plan-and-Execute / 계획 후 실행. ReAct가 매 단계 즉흥적으로 다음을 정한다면, Plan-and-Execute는 먼저 전체 계획을 세운 뒤 단계별로 실행한다. 작업 분해(decomposition)가 설계 시점에 이미 알려져 있을 때, 예측 가능한 실행을 제공한다. 매 단계 LLM이 "다음 무엇을?"을 다시 묻지 않으므로 호출 수와 변동성이 줄지만, 실행 중 상황이 바뀌면 경직될 수 있다.
멀티 에이전트 오케스트레이션 / 역할 분담. 단일 에이전트의 한계에 부딪히면, 여러 전문 에이전트(계획자, 검색자, 실행자, 평가자 등)에게 역할을 나눈다. 2026년 기준 생산 환경에서 자주 쓰이는 패턴은 다음과 같다.

[그림 4. 패턴 계보 — CoT(닫힌 루프)에서 ReAct(열린 루프)를 거쳐 멀티 에이전트로]
중요한 경고 ! 멀티 에이전트는 기본값이 아니다.
물론 반대 방향의 보고도 있다. 병렬 하위 에이전트를 선도 계획자가 조율한 멀티 에이전트 리서치 구조가 단일 에이전트 대비 큰 폭의 향상을 보였다는 내부 평가도 존재한다. 요점은 "멀티 에이전트가 우월하다/열등하다"가 아니라, 위 원칙이다. 대부분의 팀은 단일 에이전트가 천장에 닿기 전에 멀티 에이전트로 넘어가 조정 복잡도라는 비용을 떠안는다.
이것은 서론의 "에이전트 인플레이션"이 한 단계 위에서 반복되는 현상이다. 단일 호출 → 에이전트의 과설계가 있듯, 단일 에이전트 → 멀티 에이전트의 과설계가 있다.
참고
원리를 실제로 적용한 사례다. 손님 대화 로그를 분석해 사장님에게 "무엇을 신규 소싱하거나 재입고해야 하는지"를 알려주는 셀러 어드민을 만들었다. 핵심 설계 결정은 손님용 기능과 사장님용 기능에 서로 다른 범주를 의도적으로 적용한 것이다.
손님 챗봇 / RAG로 충분한 경우. 손님 챗봇은 상품을 추천하고 답한다. 여기엔 RAG를 적용했다. 상품 목록을 프롬프트에 주입하고 LLM이 이를 참고해 답한다. 도구 호출도 루프도 없다.
왜 충분한가. 손님 응답은 (1) 빠르면 좋고, (2) 틀려도 치명적이지 않으며, (3) 추가로 무언가를 "확인하여 판단"할 필요가 없다. 경계의 기준에 따르면, 여기엔 도구가 추론의 일부로 들어갈 이유가 없다. 에이전트화는 과설계다.
어드민 분석 / 에이전트가 정당화되는 경우. 반면 어드민의 소싱 제안은 다르다. "이 상품을 들여오라"는 제안은 사장님의 의사결정에 직접 영향을 준다. 여기서 환각이 발생하면 실제로 판매 중인 상품을 두고 "없으니 새로 들여오라"고 하면 잘못된 사업 판단으로 이어진다. 앞서 본 두 조건(환각 감소·실패 적응)이 모두 요구되는 지점이다.
그래서 어드민은 단계를 나눈 에이전트로 설계했다.
[0] 로그 적재 / 대화를 텍스트로 직렬화 (LLM 없음)
[1] 의도 분류 / 손님들이 무엇을 찾았는가 (LLM)
[2] 미충족 수요 / 찾았으나 구매하지 못한 것만 (LLM)
[3] 소싱 제안 / 실제 재고를 도구로 확인 후 판단 (LLM + tool calling)
[4] 검증·저장 / 스키마 검증 후 영속화
3단계에서 LLM에게 주는 도구는 이렇게 생겼다.
const checkInventory = tool({
description:
'여러 상품 키워드의 재고를 한 번에 확인한다. ' +
'각 키워드를 name에 포함하는 상품의 id, name, stock을 키워드별로 반환한다.',
inputSchema: z.object({
queries: z
.array(z.string())
.describe('확인할 모든 미충족 수요의 핵심 상품 키워드 목록'),
}),
execute: async ({
도구는 세 부분으로 이뤄진다. description은 LLM이 읽고 "언제 이 도구를 쓸지" 판단하는 근거, inputSchema는 LLM이 채워야 할 인자의 형틀, execute는 실제 DB를 조회하는 우리 코드다. 판단은 LLM이, 실행은 코드가 맡는다 뒤의 신뢰·권한 절에서 다룰 권한 분리가 여기서 시작된다.
핵심은 3단계다. 미충족 수요에 대해 "신규 소싱"인지 "재입고"인지를, LLM의 추측이 아니라 실제 재고 조회로 가른다. LLM이 "이것이 실제로 존재하는지 확인하겠다"고 판단하면 위 도구를 호출한다. 이것이 ReAct의 Action-Observation이다 — LLM이 행동(재고 조회)하고, 관찰(실제 재고)을 보고, 다음 판단(소싱/재입고)을 내린다.
같은 LLM, 다른 신뢰 요구. 이 대비가 사례의 요점이다. 손님(RAG)과 어드민(에이전트)은 동일한 LLM을 쓰지만, 요구되는 신뢰 수준이 다르다. 빠른 응답으로 충분한 곳엔 RAG, 데이터로 검증된 판단이 필요한 곳엔 에이전트. 도구 호출은 LLM을 수동적 텍스트 생성기에서 외부 시스템과 상호작용하는 능동적 행위자로 전환시킨다. 어느 범주를 쓸지는 기술의 우열이 아니라 작업의 신뢰 요구가 결정한다.
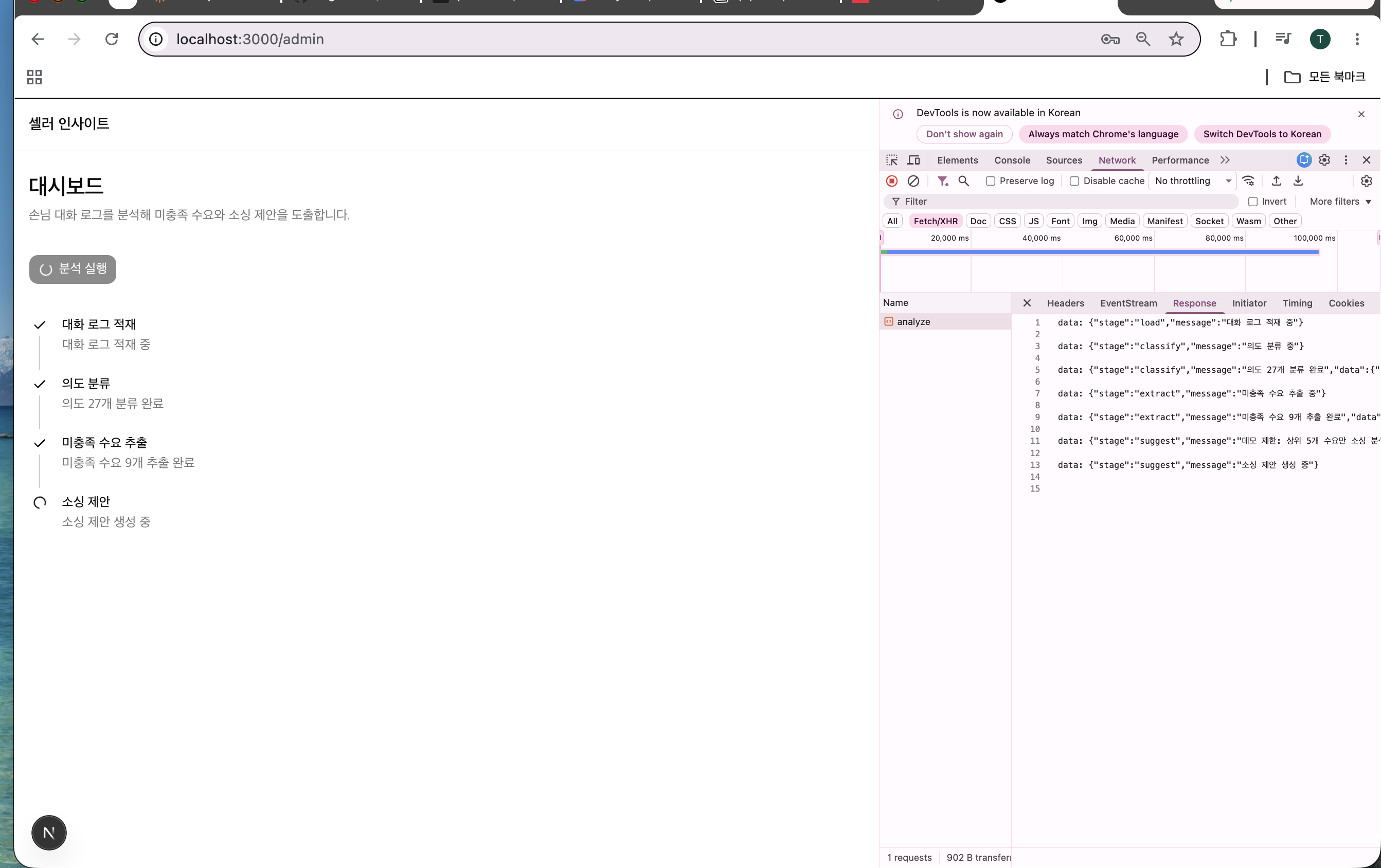
[그림 5. 어드민 분석 진행 화면 — 의도 분류·미충족 추출 단계가 SSE로 실시간 수신되며 진행된다]
참고
원리를 코드로 옮기면 이론에 없던 실패들을 만난다. 에이전트는 단일 호출에 없는 고유한 실패 모드를 가지며, 이를 아는 것이 설계의 절반이다. 아래는 대표적 다섯 가지다.
도구를 호출하지 않음 (Skipped Tool Call). LLM이 "도구 없이도 답할 수 있다"고 판단해 도구를 건너뛰고, 자기 기억으로 답을 지어낸다. 환각을 막으려 둔 단계에서 환각이 발생한다. 실제 사례 — 위 어드민 구현의 첫 버전에서 check_inventory가 한 번도 호출되지 않아, 실재하는 상품을 두고 "없음, 신규 소싱"이라는 환각이 나왔다.
원인은 호출 방식에 있었다. 처음엔 도구를 등록만 하고, 쓸지 말지를 LLM에 맡겼다.
// 도구를 줬지만, 호출 여부는 LLM이 결정
const gather = await generateText({
model: geminiFlash,
tools: { check_inventory: checkInventory },
system: SOURCING_GATHER_SYSTEM_PROMPT,
prompt: `다음 미충족 수요들의 재고를 확인하라.\n\n${demandsPrompt}`,
});
// → LLM이 "굳이 안 써도 답할 수 있다"고 판단해 건너뜀 → 환각도구 호출을 강제하자 해결됐다.
const gather = await generateText({
model: geminiFlash,
tools: { check_inventory: checkInventory },
toolChoice: 'required', // 반드시 도구를 거치게 강제
stopWhen: stepCountIs(1), // 한 번의 호출로 모든 키워드 확인
system: SOURCING_GATHER_SYSTEM_PROMPT,
prompt: `... check_inventory를 한 번 호출하라 ...`,
toolChoice: 'required' 한 줄 차이로, 에이전트는 실제 재고를 확인한 뒤에야 답하게 됐다.
"도구를 줬다"와 "도구를 쓴다"는 다르다. 그리고 그 차이는 검증의 끝에서야 드러났다.
무한 루프 / 폭주 (Runaway Loop). 에이전트가 같은 행동을 반복한다 — 같은 것을 검색하고, 같은 도구를 부르고, 같은 결과를 받는다. 관찰을 바탕으로 믿음을 갱신하지 않을 때 생긴다. 추론 단계가 관찰을 제대로 읽지 않는 것이 원인이다. 생산 환경에서는 잘못 설정된 에이전트가 재귀적 도구 호출로 빠져들어, 어떤 과금 경보가 울리기도 전에 API 예산을 태워버린다. 대응으로 단계 수 상한(step cap), 루프 탐지, 반복 호출 차단을 둔다.
관찰 무시 (Observation Neglect). 도구는 호출했으나 그 결과를 추론에 반영하지 않는다. 무한 루프와 인지적 뿌리가 같다. 관찰을 형식적으로 받기만 하고 다음 Thought가 그것을 읽지 않는다. 열린 루프의 이점(외부 검증)이 무력화된다.
잘못된 도구 선택 (Tool Selection Hallucination). 부적절한 도구를 고르거나, 적절한 도구를 잘못된 시점에 부른다. 도구가 많아질수록 악화된다. 정의를 읽고 선택하는 모델의 능력이 도구 수 증가에 따라 저하되기 때문이다. 도구가 수십 개로 늘면 정의만으로 수만 토큰을 소비하고, 선택 정확도도 함께 떨어진다. 대응으로 동적 도구 발견(필요한 도구만 노출), 도구 수 제한을 둔다.
컨텍스트 폭발 (Context Overflow). 루프가 길어질수록 모든 Thought·Action·Observation이 컨텍스트에 토큰을 더한다. 긴 ReAct 트레이스는 빠르게 비싸진다. 실제 사례 — 위 사례에서 미충족 수요마다 도구를 따로 호출하니 호출이 5~7회로 늘어 무료 티어 한도(분당 5요청)를 넘겼다. 도구가 여러 키워드를 한 번에 받도록 바꿔 호출을 4회로 줄였다. 이때 "도구를 몇 번 부르는가"는 줄였지만 "실제 데이터로 검증한다"는 본질은 유지했다 — 에이전트의 정체성은 호출 횟수가 아니라 검증 여부에 있기 때문이다. 일반적 대응으로는 관찰 결과 요약·압축, 메모리 분리(작업/일화/절차 기억)가 있다.
궤적 차원의 환각. 최근 연구는 환각을 최종 출력이 아니라 궤적(trajectory) 차원에서 분류한다. 사실적(factual)·참조적(referential)·논리적(logical)·절차적(procedural)·범위적(scope-based) 환각의 다섯 유형이 제시되었으며, 가장 흔한 실패가 최종 출력만 보는 기존 벤치마크에서 누락된다는 점이 보고되었다. 위의 다섯 실패 모드는 대부분 이 궤적 차원에서 발생한다 — 즉 최종 답만 봐서는 잡히지 않는다. 이것이 다음 절의 평가로 이어진다.
참고
단일 호출과 에이전트는 평가 방식도 다르다. 단일 호출은 "입력→출력"의 정합만 보면 된다. 그러나 에이전트 평가는 단지 올바른 답에 도달했는지가 아니라, 올바른 방식으로 — 올바른 도구를, 올바른 순서로, 도중에 단계를 환각하지 않고 — 도달했는지를 측정한다. 앞서 본 다섯 실패 모드가 최종 출력만으로는 잡히지 않으므로, 평가도 과정을 봐야 한다.
2026년의 정착된 틀은 평가를 세 계층으로 나눈다.
결과 지표 (Outcome Metrics). 최종 목표 상태에 대한 이진(pass/fail) 판정. 단순하지만 무디다. 무언가 잘못됐다는 것은 알려주되, 어디서 왜 잘못됐는지는 말해주지 않는다.
궤적 지표 (Trajectory Metrics). 각 중간 단계를 평가한다 — 도구 선택, 추론 품질, 인자 정확성, 결정 순서. 진짜 신호가 사는 곳이 여기다. 효율성 점수(정답을 낸 궤적에 한해 측정), 환각 감소 점수, 적응성 점수 같은 차원이 쓰인다. 예컨대 적응성을 엄격히 측정하기 위해, 유효한 도구와 이름이 유사한 가짜 도구를 도구 집합에 섞고, 에이전트가 가짜 도구를 골라 "사용 불가" 오류를 받았을 때 다음 단계에서 유연하게 대안 도구로 전환하는지를 관찰하는 방법이 있다.
시스템 지표 (System Metrics). 효율·비용·신뢰성. 작업당 토큰 사용량, 지연, 도구 호출 빈도, 실패 회복률. 생산 환경에서 중요하다 — 정확히 작동하지만 질의당 50달러를 태우는 에이전트는 출시될 수 없기 때문이다.
함의 — 관찰 가능성(Observability). 전통적 APM은 요청이 200을 반환했음은 보여주지만, 에이전트가 두 번 루프를 돌았는지, 잘못된 도구를 불렀는지, 정책을 환각했는지는 보여주지 못한다. 그래서 에이전트에는 LLM 호출·도구 호출·메모리 연산을 가로지르는 구조적 추적(structured tracing)과, 멀티 에이전트 핸드오프의 부모-자식 관계를 보존하는 중첩 스팬(nested spans)이 요구된다. 앞서 본 도구 미호출 버그도, 최종 출력만 봤다면 "그럴듯한 답"으로 통과했을 것이다. 과정을 봐야 잡힌다 — 이것이 에이전트 평가가 단일 호출 평가와 근본적으로 다른 이유다.
참고
도구를 주는 순간, "LLM이 무엇을 할 수 있는가"는 보안 문제가 된다. 단일 호출은 텍스트만 생성하므로 권한 경계가 단순하지만, 에이전트는 외부 시스템에 행동을 가하므로 권한 설계가 필수다.
판단과 실행의 분리. 앞서 짚었듯, LLM은 도구에 직접 접근하지 않는다. LLM은 "이 도구를 이 인자로 실행하라"는 요청만 생성하고, 실제 실행은 애플리케이션 코드의 함수가 수행한다. 이 분리가 안전의 토대다. LLM은 우리가 정의한 도구만 쓸 수 있고, 그 도구가 허용한 범위 밖을 건드리지 못한다. 잘못된 도구 사용은 부적절한 데이터 접근으로 이어져 에이전트의 보안 취약성을 키울 수 있으므로, 도구가 노출하는 권한 자체를 최소화해야 한다.
최소 권한과 읽기 전용. 사례의 check_inventory는 읽기 전용이다. 재고를 조회할 뿐 변경하지 않는다. 에이전트가 쓰기 권한을 가질 이유가 없으면 주지 않는다. 또한 분석 단계는 전체 데이터를 읽어야 하므로 권한이 높은 서버 전용 접근으로 돌지만, 그 자격증명이 클라이언트로 새지 않도록 서버 경계에 격리했다. 저장 단계는 분석과 분리해, 더 낮은 권한(소유자 본인만 쓰기)으로 수행했다. 권한을 단계별로 쪼개, 각 단계가 필요한 만큼만 갖게 한 것이다.
출력을 신뢰하지 않기 — 두 겹의 검증. 에이전트의 출력은 그대로 신뢰할 수 없다. 두 겹으로 검증한다.
참고
지금까지의 논의를 뒤집으면, 에이전트를 쓰지 말아야 할 신호가 분명해진다.
이는 서론(단일 호출 vs 에이전트)과 패턴 계보 절(단일 에이전트 vs 멀티 에이전트)에서 본 경고의 일반형이다. 복잡도는 기본값이 아니라, 측정된 한계에 의해 정당화되어야 한다.
참고
핵심 판별은 하나로 수렴한다 — 도구 호출이 추론의 일부인가, 전후 처리인가. LLM이 그때그때 "이것을 확인해야겠다"고 판단해 도구를 쓰고 그 결과로 추론을 이어간다면 에이전트다. 우리가 정한 순서대로 데이터를 넣어줄 뿐이라면, 그것은 잘 만든 호출이다.
도구를 준다고 쓰는 것이 아니고, 만든다고 작동하는 것이 아니며, 복잡하다고 나은 것이 아니다. 경계를 알고, 필요한 곳에만 쓰고, 작동하는지 끝까지 확인하는 것 — 에이전트를 다루는 일의 대부분은 거기에 있었다.
이 글의 사례로 든 셀러 어드민은 그 원리를 작은 규모로 시험해본 자리였다. 손님에겐 RAG로 충분했고, 사장님의 판단엔 도구로 검증하는 에이전트가 필요했다 — 그 경계를 직접 그어본 것이 가장 큰 수확이었다.